On the early morning of November 25, Anthropic released its most powerful AI model to date, Claude Opus 4.5. The company claimed that the new model has achieved “state-of-the-art performance” in software engineering tasks, further intensifying the competition with rivals such as OpenAI and Google.
Claude Opus 4.5 performed exceptionally well in Anthropic’s software engineering tests, surpassing a host of competitors including Gemini 3 Pro and GPT-5.1.

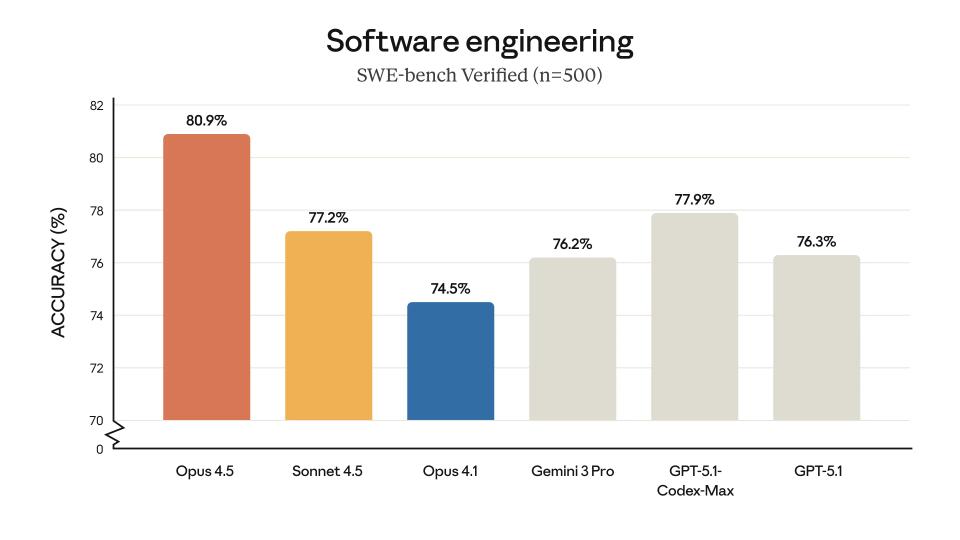
According to company data, the model achieved an accuracy rate of 80.9% in SWE-bench Verified, a benchmark test for evaluating real-world software engineering capabilities. This performance outperformed OpenAI’s GPT-5.1-Codex-Max (77.9%), Anthropic’s own Sonnet 4.5 (77.2%), and Google’s Gemini 3 Pro (76.2%).
At the same time, Anthropic significantly reduced the pricing of this model: the cost for input tokens dropped to 5 per million,and for out put tokens to25 per million. This represents a reduction of about two-thirds compared to its predecessor, Claude Opus 4.1 (input at 15 per million and out put at 75 per million).
The price reduction makes cutting-edge AI technology more accessible to a wide range of developers and enterprises, while also putting pressure on competitors in terms of both performance and price.
Demonstrating Better Judgment in Real-world Tasks
Testers generally reported that the new model exhibits stronger judgment and intuition across various tasks. They described this progress as the model beginning to grasp the “essence” in real-world situations.
“This model seems to have suddenly ‘clicked’,” said Albert, the head of developer relations. “Its intuition and judgment in handling many real-world problems make it feel like a qualitative leap compared to previous models.”
Albert further illustrated with his own work: In the past, he only used AI to collect information and was skeptical about their ability to integrate and prioritize it. Now, with Opus 4.5, he has started to delegate more complete tasks. By connecting to Slack and internal documents, the model can generate coherent summaries that highly match his expectations.
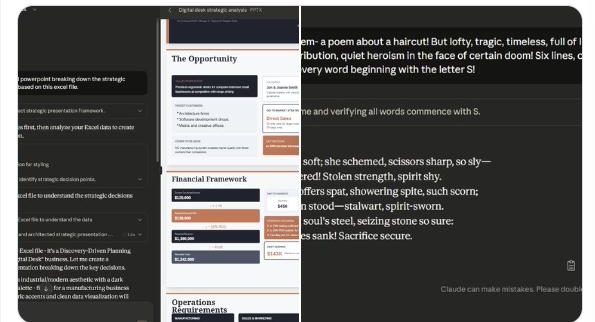
Ethan Mollick, a professor at the Wharton School of the University of Pennsylvania and co-director of the Generative AI Lab, commented after testing that the new model’s capabilities are indeed at the forefront of technology. Its most significant improvement lies in practical applications, such as cross-software operations (e.g., creating a PowerPoint presentation from Excel).
Surpassing All Human Engineers in Core Engineering Tests
Claude Opus 4.5 set a new record in a high-difficulty engineering assessment conducted internally by Anthropic. This assessment was originally a timed programming test designed for performance engineer positions, requiring candidates to complete it within two hours to evaluate their technical skills and problem-solving judgment.
Anthropic revealed that by adopting the “parallel test-time computation” technique, which aggregates multiple problem-solving attempts by the model and selects the best result, Opus 4.5’s final score surpassed that of all human engineers who had ever taken the test.
Under unlimited time conditions, when running in its dedicated coding environment, Claude Code, Opus 4.5’s problem-solving performance was on par with the highest-scoring human engineers in history.
However, the company also admitted that such tests cannot measure other key professional skills, such as teamwork, effective communication, or professional intuition developed over years.
Core Benchmark Test Token Consumption Reduced by 76%
In addition to breakthroughs in raw performance, Anthropic regards efficiency improvements as a core competitive advantage of Claude Opus 4.5. The new model significantly reduces the number of computational tokens required to achieve the same or even better results.
Specific data shows that at the “medium” input level, Opus 4.5 can achieve the same top score as Sonnet 4.5 in the SWE-bench Verified test, while the output token consumption is reduced by 76%. Even when pursuing maximum performance at the “high” input level, its performance improves by 4.3 percentage points compared to Sonnet 4.5, while token usage is still reduced by nearly half (48%).
To give developers more precise control, Anthropic introduced a new “input” parameter. Users can dynamically adjust the amount of computational work the model invests in each task through this parameter, thus finding the optimal balance between performance, response speed, and cost.
Mario Rodriguez, Chief Product Officer of GitHub, also confirmed similar findings: “Early tests show that Opus 4.5 outperforms our internal coding benchmark while halving token consumption, especially excelling in complex tasks such as code migration and refactoring.”
Albert provided a technical interpretation of this phenomenon: Claude Opus 4.5 does not directly update its underlying parameters but continuously optimizes the tools and methods for solving problems. “We see it iteratively refining its task skills, improving the final results by autonomously optimizing its execution methods,” he explained.
This self-evolution capability has extended beyond the programming field. Albert revealed that the model has shown significant improvements in scenarios such as professional document generation, spreadsheet processing, and presentation creation.